The Open Web Application Security Project (OWASP) is a 501c3 not-for-profit worldwide charitable organization focused on improving the security of application software. Our mission is to make application security visible, so that people and organizations can make informed decisions about true application security risks. Everyone is free to participate in OWASP and all of our materials are available under a free and open software license.
Tuesday, October 30, 2018
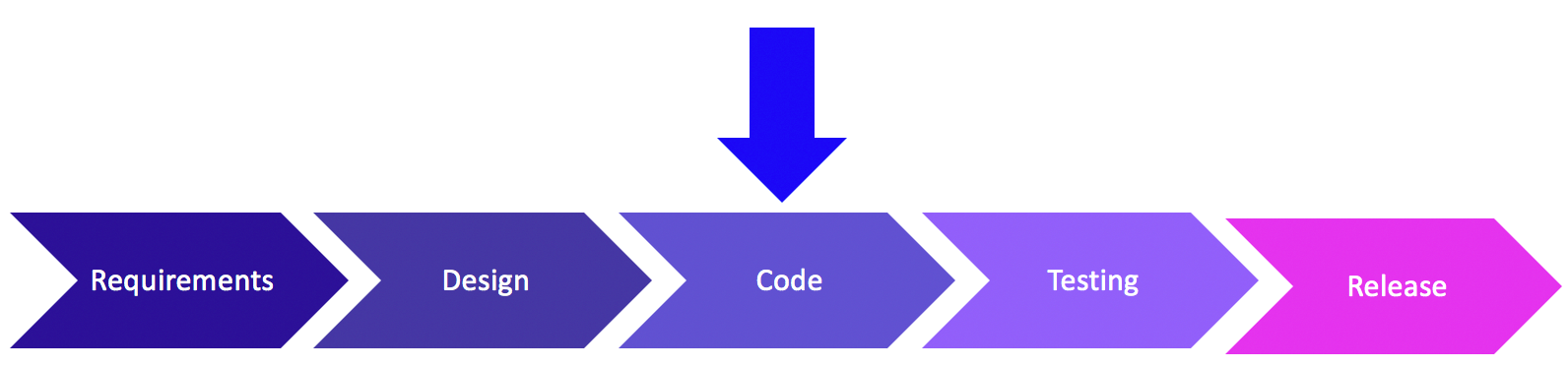
Pushing Left, Like a Boss — Part 5.1 — Input Validation, Output Encoding and Parameterized Queries
After writing up my secure coding guideline and finding it was over 11 pages, my editor informed me that it was inappropriate to publish as a single blog post. With compromise in mind, and in the hopes that people continue reading my blog, I agreed to break up the guideline into several shorter posts. The first few posts will be in-depth details of several of the items for the guideline, then a final post which will be a short, concise guideline, with links to each of the previous posts for further explanation.
Image Credit: WOCTechChat
Input Validation, Output Encoding and Parameterized Queries
Input Validation
Any input that you receive, from anywhere, must be validated to ensure that it is what you are expecting. For instance:
It is the right type of data? — Date/string/integer/float/etc.
It is within the appropriate range for size? Is it too long? Too short? Does that day actually exist? (June 31st is not a real day)
Is the data is appropriate? — If you are expecting a username, why does it contain characters other than a-z, A-Z, 0–9? If the field is for the date of a future event, why is the date entered in the past? Business logic should be applied here.
Is the data is in the correct format? — If it’s a call to an API, is the call following the protocol of requested input? Is the XML in the correct format? Is it MM/DD/YY, DD/MM/YY or YYYY/DD/MM?
The most important thing is ensuring that the data you are receiving is*valid*. If it is not valid, reject it, then issue an error to the user. Donottry to sanitize it, that is where many programmers get into trouble. Just tell the user what they entered was wrong and let them try again.
Note #1: all sanitation of input should be performed on theserver-side(definition below), not the client-side. The reason for this is that client-side validation is performed in JavaScript, which can be easily circumvented with a web proxy, such asOWASP Zap. If you require speed, you can validate on the client-side AND the server-side, but the final decision must always be made server-side.
Client-side versus server-side: Client-side actions happen on the user’s computer, generally in the browser. Client-side actions can often be easily manipulated with a web proxy, for instance javascript input validation. Server-side actions are things that happen on the server where your web app is hosted, and hence cannot be changed with the use of a web proxy.
Note #2: Awhitelistis always recommended when performing input validation.
Whitelist versus blacklist: A blacklist is a list of characters that you do not want to allow (for instance tags that you may think would be part of a script). A blacklist is a list of “known bad”characters, which is very difficult to get right, and often simple for an attacker to avoid. A whitelist is a a list of “known good” characters that you will accept. For instance, when you want someone to create a username, you only allow [a-z, A-Z, 0–9]. If a character is not in the list of “known good”, then it is rejected, plain and simple.
When displaying information to the screen, if it was received from a data source (rather than being part of the labels and other information programmed into the interface of the application), it needs to be output encoded. When something is output encoded, any ‘power’ it has is stripped away, and it is treated only as text. This means that if a script was accidentally passed into the application, API or database, it would be rendered as text, not as a script, when it is output by the program.
When we spoke about “Defense in Depth”, the layering of security measures, this is a perfect example of this in practice; only accepting valid input, then output encoding it just to be sure.
This is a perfect example of the layering of security measures in practice, as we covered in “Defense in Depth.” Only valid input should be accepted into the program, then we output encoded it just to be sure.
Many programming frameworks have output encoding automatically added, such as .Net Core.
Image Credit: WOCTechChat
Parameterized Queries
When sending queries to the database it is important that we useparameterized queries(also known as prepared statements), rather than inline SQL or other database languages. Inline SQL is the pasting of user input together with database query language, then submitting it directly to the database for execution, which is a highly dangerous activity.
The reason for this is that if you put the user input into parameters, it will either 1) be the correct data type and function normally, or 2) be incorrect and it will fail. For instance, if you inject a script into a date field, it will cause the query to fail. It also strips any special powers that some characters may have from the data within parameters, similar to output encoding. This strategy of using parameterized queries (such as stored procedures) is a huge win against any sort of database injection attack.
* For those of you who are unaware, injection attacks are the#1 most damaging and dangerous typeof web application attack, and are generally considered to be rated as “critical” if found in a live application.
In the previous articlein this series we discussed secure design concepts such as least privilege, reducing attack surface, failing safe and defense in depth (layered protection). In this article, we are going to talk about secure coding principles which could be used to help guide developers when implementing security controls within in software.
As we discussed before, a security flaw is a design problem, while a security bug is an implementation problem (a problem in the code). Whoever wrote that code had the best intentions, but may not have had enough information, time or guidance on how to do it correctly.
Coding Phase of the SDLC
What is “secure coding”?
Sometimes called “defensive coding”, it is the act of coding with security in mind, andguarding against accidentalor intentional misuse of your application. It is to assume that your application will be used in a myriad of ways(not necessarily just the way that you intended) and to code it accordingly.
Why is it ‘secure coding’ important?
I’m not going to answer that. If you are reading this blog, you already understand why secure coding is important. I think the real question here is: “How do I explain how important it is to developers? To project managers? To executives? How do I get them to give me time in the project for it?” I’m asked this quite often, so let me give you a few options.
You can explain using statistics and numbers, to predict the financial implications of a major security incident or breach. You can provide a cost/benefit analysis of how much less an AppSec program would cost. I used this approach and I was approved to launch my first AppSec program.
You can explain the business implications of a major incident, the loss of reputation or legal implications that would result from a major incident or data breach. I tend to use this when trying to justify large changes such as creating a disaster recovery site, or an AppSec advocacy program, or giving developers security tools (that tends to scare the pants off of most management types).
You can create a proof of concept to explain a current vulnerability you have in your product, to show them directly the consequences that can occur. This might lose you some friends, but it certainly does get your point across.
You can sit down with whoever is blocking you and have a real discussion about why you are worried about your current security posture. Explain it to them like they are a highly intelligent person, who happens to not know much about security (which means respectfully, and with enough detail that they understand the gravity of the situation.) It is at this point that I would tell them that I need them to sign off on the risk if we do not correct the problem, and that I can no longer be responsible for this. It is at this point that either 1) I get what I want or 2) I know this is no longer my responsibility.
Why are users the worst?
The one thing that you should always remember when coding defensively is to assume that users will do something that you did not plan on.
In the next post in this series I intend to publish a secure coding guideline. But before we continue onto that, please allow me to present my#1 adviceon this topic:always use the security features in your framework. If your framework passes an anti-CSRF token for you, output encodes your data, or handles session management, use those features!*Never* write your own security control if one is available to you in your framework.This is especially true of encryption; leave it to the experts. Also, whenever possible, use the latest and greatest version of your framework — it’s usually the most secure version. Keep your framework up-to-date for less technical-debt and more cool features.
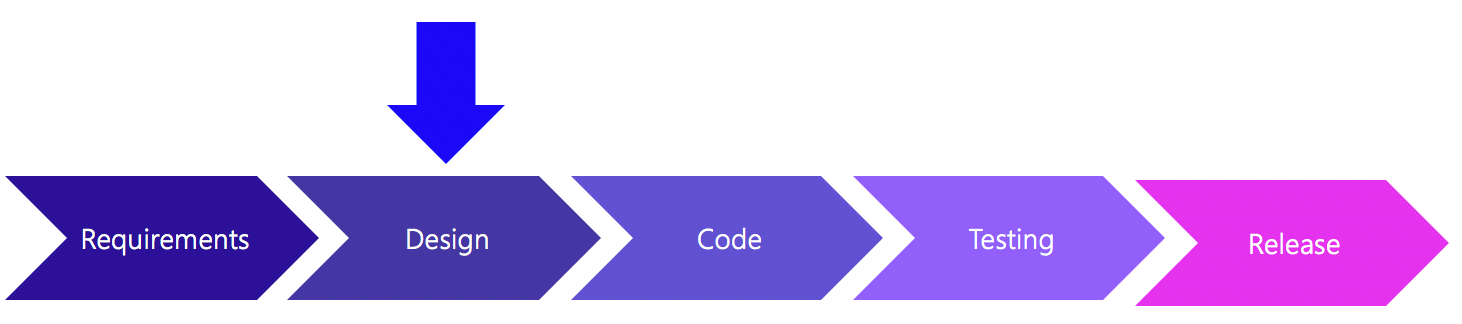
In theprevious articlein this series we discussed security requirements. When making any product, requirements are a must, and ensuring you have security built into your requirements from the beginning is the first step to ensure your final product will be of high quality. In this article we will discuss the next phase of the system development life cycle: Design.
Design Phase of the System Development Life Cycle
When designing software applications, software architects not only need to worry about what the customer has asked for (business requirements),functional requirements(user requirements, scheduling, system requirements), but alsonon-functional requirementsthat are often taken for granted, such asusability,quality, and of course,security.
Unfortunately, when we design applications we often forget to think of all the angles, focusing more on ensuring it works, rather than ensuring that it *only* works the way we have intended. This is wherethreat modelling comes in, the process of identifying potential threats to your business and application, and ensure that proper mitigations are in place. This article will focus on what concepts we need to consider when designing for security, and in a future article we will discussthreat modelling.
Secure by design, in software engineering, means that the software has been designed from the ground up to be secure. Malicious practices are taken for granted and care is taken to minimize impact when a security vulnerability is discovered or on invalid user input. — Wikipedia
Design Flaw VS Security Bug
A security flaw is an error in the design of the application that allows a user to perform actions they should not be allowed to do. Malicious or damaging actions. This is a flaw, a problem with the design. We use secure design concepts, security project requirements and perform threat modelling in attempts to avoid or minimize opportunities for design flaws.
A security bug is an implementation issue, a problem with the code, that allows a user to use the application in a malicious way. We perform code review, security testing (many types, during different stages of the project), provide secure coding training, and use secure coding concepts and guidelines in order to protect against security bugs.
Discovering a flaw late
The later you fix a problem in the SDLC, the more it will cost.An article fromSlashdotstates that a bug found in requirements may cost $1 to fix, while in design $10, coding $100 and in testing or release $1000.There are many different estimates of cost all over the internet, but instead of using ‘guesstimates’ to try to explain the idea, let me tell you a story.
Imagine you and your spouse have been saving for years and you are having your dream home built for you. It’s almost done, they are putting on the handles for the cupboards, and rolling out the carpets. It’s at this point that you look at your partner and say, “Oh honey, we have seven children, maybe we should have asked for more than one bathroom?”
Adding a bathroom this late in the construction will cost quite a bit, and make your project late, but you know you cannot continue with only 1 bathroom. You speak to the construction company and they explain that you will have to sacrifice a bedroom to add two more bathrooms or make the living room 1/2 the size. It will also mean your family can’t move in for another month. It will cost an arm and a leg.
This is the same situation for software. When you make design changes last minute they aren’t always pretty, they almost always make you miss deadlines, and they are extremely expensive.
The “not enough bathrooms” problem is something that threat modelling would have found. This is something that secure design concepts might have made visible more early on. This problem is the reason that we need to begin security at the start, not the end, of all projects. This is why we need to ‘push left’.
Secure Design Concepts
With this in mind, let’s talk about several secure design concepts that should be discussed when designing software applications.
The idea of defence in depth is that security should be applied in layers; one level of defence is not necessarily enough. What happens if an attack gets past your Web Application Firewall (WAF)? I certainly hope you have secure code back there. It just doesn’t make sense to only use one precaution if you can use two or more (assuming it’s not “too expensive”).
For instance, if you call the same input sanitization function every time, why not call it for data from the database? Who knows if whoever put it there sanitized it first? Maybe something was missed? Maybe data was dumped in there from a 3rd party? Sanitizing it as it comes out of the database will take fractions of a millisecond. I wouldn’t call that expensive.
MinimizeAttack Surface(removing unused resources and code)
The smaller your app, your network, or even your country, the less you have toworry about protecting. If you haven’t released that new feature yet, why do you have the code in your app,but the button “hidden”? If you have a secret page, attackers could find it. If you have a ton of your code commented out, why is it still in the final product? If you have virtual machines or other resources on your network, but you aren’t using them, why are they still there (and likely on the internet)? Doing regular “clean up” of your resources, and ensuring you remove commented code, as well removing unused or “secret” features, are all great ways to ensure there are less options for malicious actors to attack.
Least Privilege
Giving everyone exactly how much access and control they need to do their jobs, but nothing more, is the concept ofleast privilege. Why would a software developer need domain admin rights? Why would an administrative assistant need administrative controls on their PC? This is no different for software. If you are usingRole Based Access Control(RBAC) to give users different abilities and powers within your application, you wouldn’t give everyone access to everything, would you? Of course not. Because the more people with access, the more risk there is of someone causing a security issue.
This means several things in regard to developing software, and some of it you’re probably not going to like.
Not only does the software itself need to follow the rules of leastprivilege, but that least privilege must apply tothe people creating the software. Software developers are a huge risk to IT security, if one has malicious intent, or has a bad day and acts carelessly, if they are given too much access… The consequences can be severe.
Let’s leave that there for now and continue further into the secure design rabbit hole.
Fail Safe or Fail “Closed”
Whenever something fails in your application it must *always* fail to a known state, preferably it’s original one. Let’s say you’ve run a transaction to transfer money from one account to another, and there’s an error part way through; you certainly wouldn’t want that money to be in limbo. You would want the money returned to the original account, the user given an error that they need to try again, and the system to log whatever happened. You would not want it to fail into an unknown state, uncertain of where the money is, or if it was transferred multiple times, or if it disappeared altogether. Failing safe means rolling back the transaction and starting again, and handling errorsgracefully.
Use Existing Security Controls(do not write your own)
I’m sure that many of you were just like I me when I was a new software developer: I thought I was the bee’s knees. I was sure that whatever I wrote was THE BEST version ever created. The fastest and definitely the most efficient. But now that I’ve got a few more years under my belt, and perhaps a bit of maturity, I’ve realized that it’s usually best to leave certain things to the experts, and only write custom code when it is truly needed. This means if you are going to performencryption,input sanitization,output encoding,use keysorconnection strings, or anything else that would be considered a security control, you should use the one available to you in your framework or platform.
When you put comments in your code, ensure that you never save passwords, connection strings, or anything else sensitive. This includes your email address, insider-information about your application, and anything else that could allow an attacker a leg up in regards to attacking your application or organization.
Re-authentication for Important Transactions(avoiding CSRF)
Cross Site Request Forgery(CSRF) is a vulnerability first defined byOWASP, where an attacker convinces the victim to click on a link, the link triggers a transaction within an application (let’s say the purchase of a fancy new TV, to be shipped to the attacker), and because the user was already logged into that account (who doesn’t leave their browser open for days on end?), the vulnerable web application completes the transaction (purchase) and the user is none-the-wiser, until the bill arrives and it is already too late.
The best way to defend against this is to ask the user for something that only the user could provide, before every important transaction (purchase, account deactivation, password change, etc.). This could be asking the user to re-enter their password, complete a captcha, or for asecret tokenthat only the user would have. The most common approach is thesecret token.
Pro Tip: users hate captchas.
Authorization
Always use the authorization functionality available to youin your framework. I know we covered this before, but there’s a reason why everyone does it one of the following ways:
Role-Based
Claims-Based
Policy-Based
Resource-Based
Segregation of Production Data
Your production data should not be used for testing, development, or any other purpose than what the business intended. This means a masked (anonymized) dataset should be used for all development and testing, and only your ‘real’ data should be in prod.
This means less people will have access to your data; a reduced attack surface. It also means less employees peeking on personal data. Imagine if you have been using a popular messaging platform and you found out that employees were reading your messages, which you thought were private. This would be a violation of your privacy, and most likely also the user agreement. Segregation of production data would eliminate most opportunities for this type of threat.
Threat Modelling(affectionately known as ‘evil brainstorming’)
Threat modelling, in it’s simplest of forms, is a brainstorming session in search of defining all threats that your application, system or product will likely face. Will people try to intercept your data and sell it on the dark web? Would it have any value if they did? What harm could come if it was? How can we protect against this? These are some of the types of questions you may find yourself doing during a session. You would then test your app and review it’s design to ensure you have properly mitigated these threats.
Threat modelling is such a large topic, that it merits it’s own blog post, as mentioned earlier.
Protection of Source Code
I realize that many people will argue with me that “Security Through Obscurity” is not a true defense tactic, but I beg to differ. It should never be your *only* defence, but if it is one of many, why not? Many companies do not put their code in open repositories in order to make it much more difficult for competing companies to try to replicate their products. Yes, a malicious actor can try to reverse engineer Windows 10, but who has that kind of time?
Is this defense foolproof? Certainly not. Would I put my code for an unreleased and/or highly valuable product in a publicGitHubrepo? I think not.
Error Handling
In order to make our applications appear professional we should always catch our errors; no one wants to see a stack trace all over the screen. But there are security concerns to be considered as well.
When a stack trace or unhandled error is shown to the user, it gives details to malicious actors as to what technology stack you are running or other information that could potentially help them plan a better attack against you.
Always catch your errors.
Logging and Alerting
We log security issues so that others may have the joy of auditing later… All kidding aside, if important things are not logged, when there is a security investigation, investigators have nothing to work with. And alerting is to ensure people know about problems in a timely manner.
Ensure you log anything important an investigator may need, but be careful not to log any sensitive information such as SIN numbers, passwords, etc.
Sensitive Data
Label all of your applicable data as sensitive when you design your data formats and ensure the application treats it that way. Design your app with protecting sensitive data in mind.
Up next in part 4we will discuss secure coding concepts that can be adopted in order to avoid common security bugs (implementation issues).